
- What are microarrays?
- How microarrays are read?
- The problem we're addressing – noise
- Prior works
- Synthetic data generation
- Discussion on metrics and alternative denoising methods
- New metric for microarray denoising models
- New state-of-the-art model for microarray denoising
- Q&A
- Dust particles and dirt that gets onto the glass slide during preparation
- Noise from the scanning process
What are microarrays?

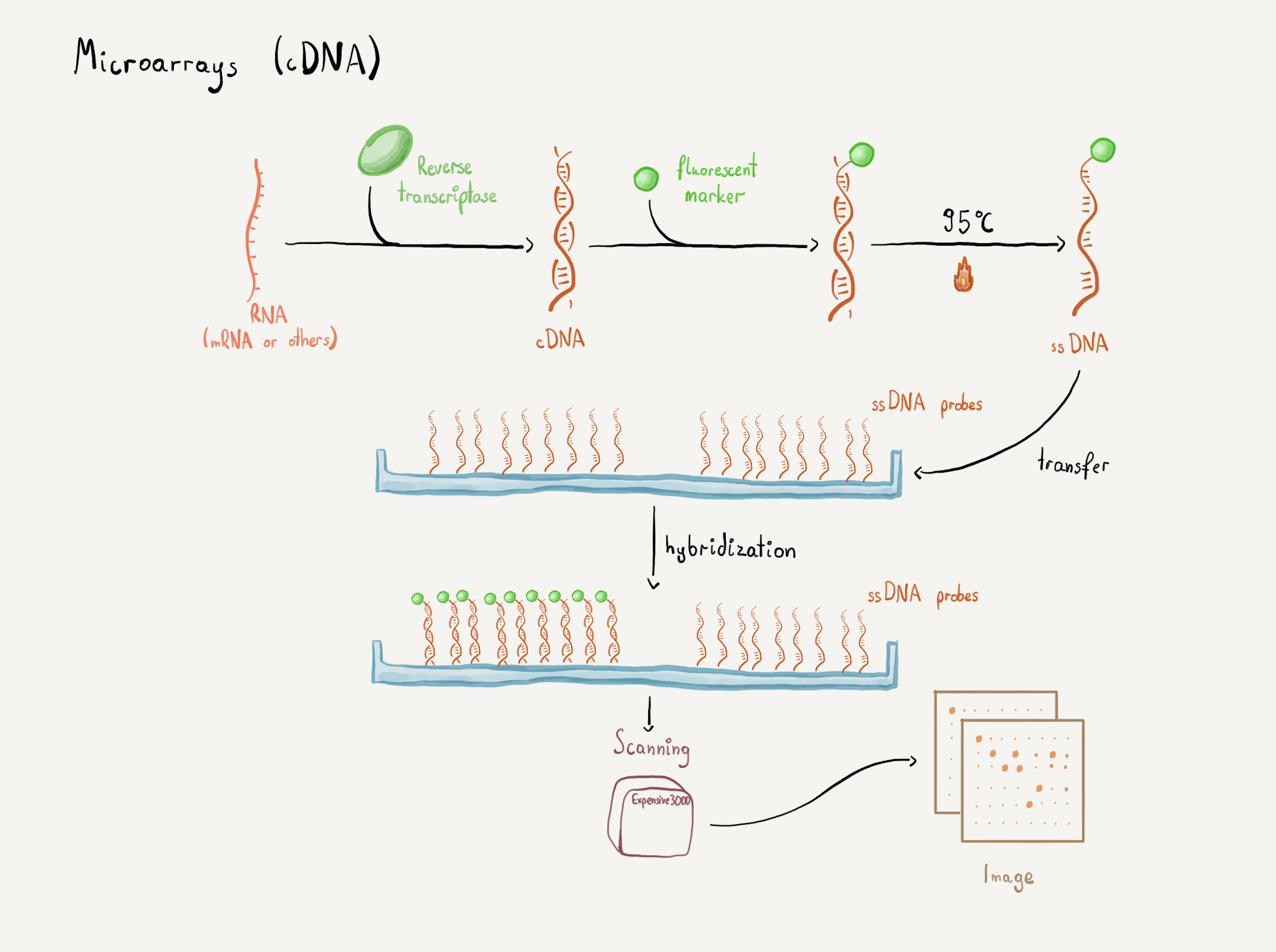
Reading information from microarray images
Suppose you are given a virus that has just 4 genes in its genome and you want to study which genes are active in the early infection stage vs. late infection stage.
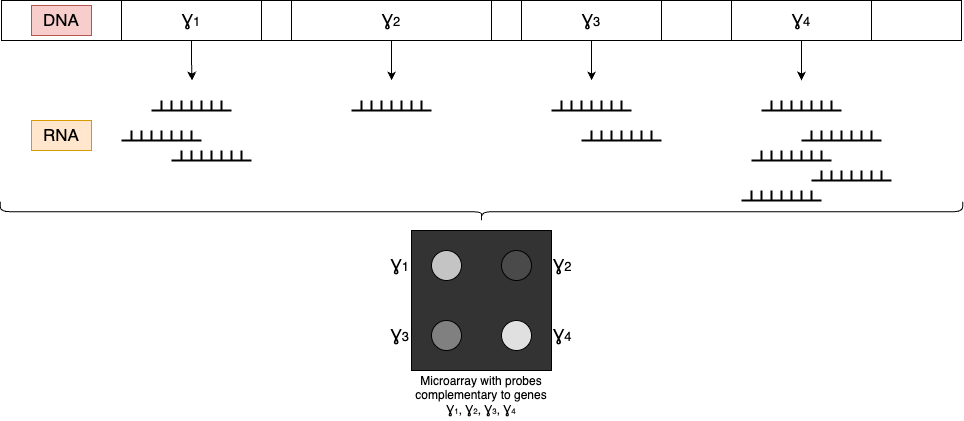
But what's the problem?
Noise:
Repeating experiments in a wet lab is expensive

But it's not great...

Denoising Autoencoder
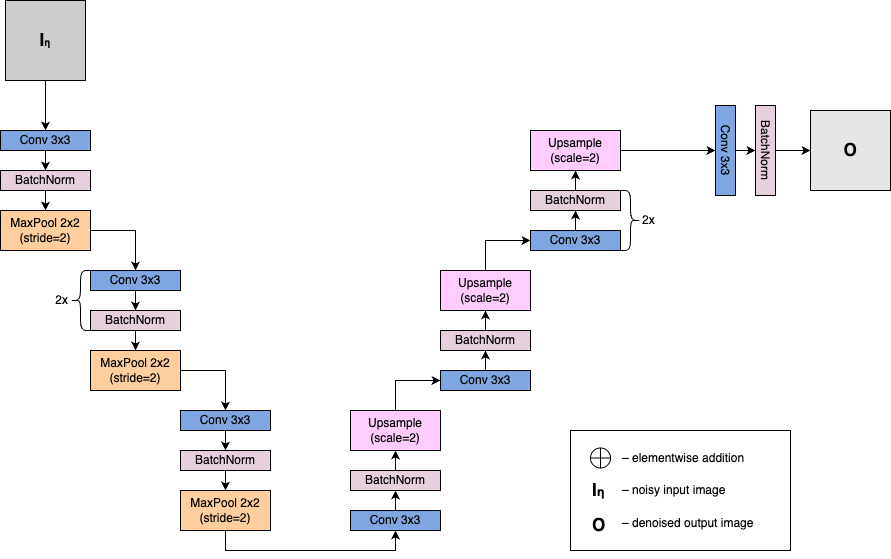
Idea: why don't we generate our own data?


Restormer [2]
Results were so good we couldn't believe our eyes



Left-to-right: (1) input, (2) Restormer output, (3) ground-truth
Then we took a closer look...
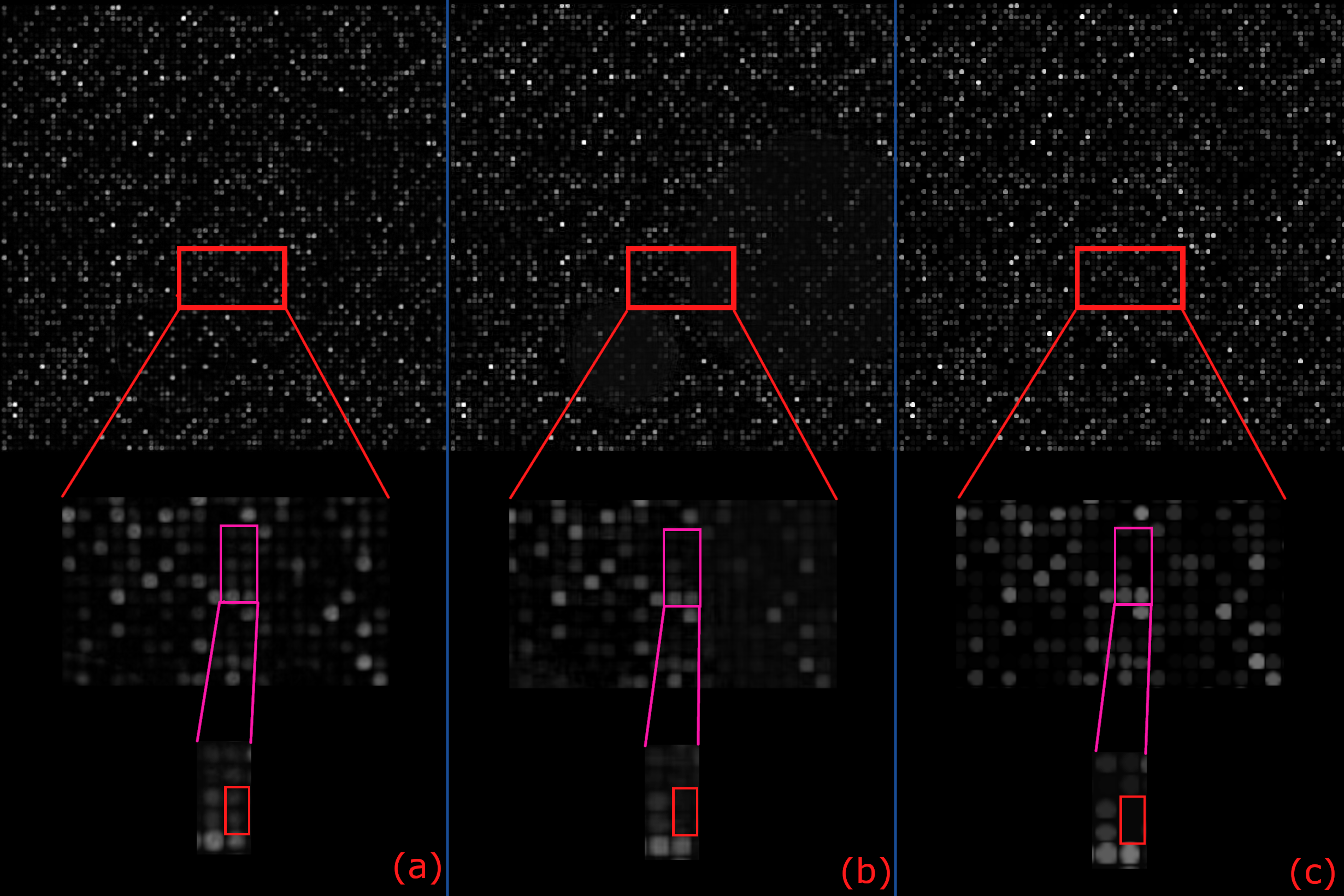
(a) Restormer, (b) our best-performing model, (c) ground-truth
OK, but how does SADGE work?
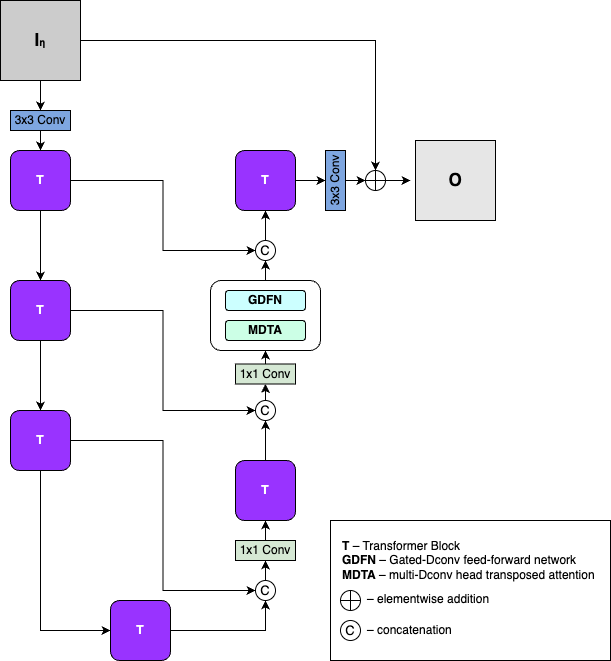
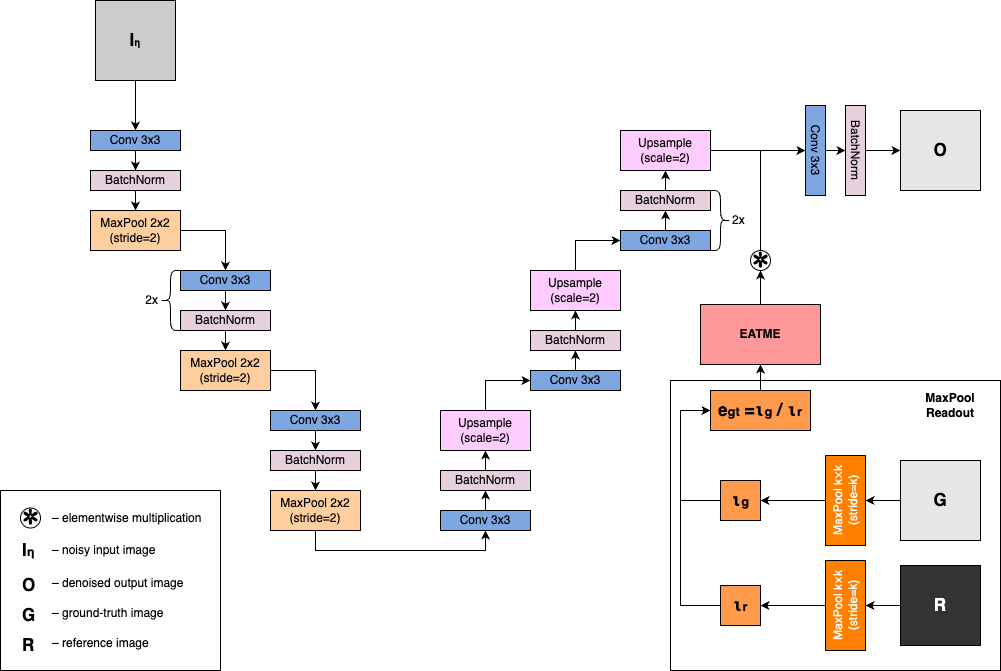
Introducing EATME
Elementwise Attention-like Transform for Microarray Enhancement (EATME)
References
[1]: A. Mohandas, S. M. Joseph, and P. S. Sathidevi, ‘An Autoencoder based Technique for DNA Microarray Image Denoising’, in 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India: IEEE, Jul. 2020, pp. 1366–1371. doi: 10.1109/ICCSP48568.2020.9182265.
[2]: S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, ‘Restormer: Efficient Transformer for High-Resolution Image Restoration’, Mar. 11, 2022, arXiv: arXiv:2111.09881. doi: 10.48550/arXiv.2111.09881.